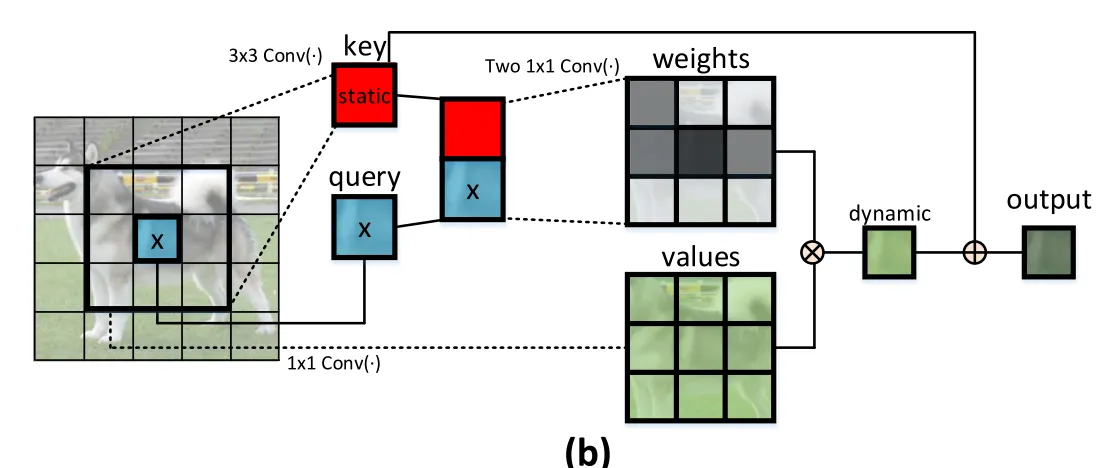
CoT是一种视觉Transformer模型,主要应用于图像分类和目标检测等计算机视觉任务。其设计的初衷是为了解决在处理自然场景图像时,图像中不同区域之间存在的复杂的交互关系问题。传统的Transformer模型在处理图像时只能看到图像的全局信息,无法有效地处理这些局部的交互关系。CoT引入了一种新的局部-全局交互机制,可以更好地处理这种问题。同时,CoT还采用了一种新的层次化的特征融合方式,可以提高模型的性能。
CoT是一种视觉Transformer模型,主要应用于图像分类和目标检测等计算机视觉任务。其设计的初衷是为了解决在处理自然场景图像时,图像中不同区域之间存在的复杂的交互关系问题。传统的Transformer模型在处理图像时只能看到图像的全局信息,无法有效地处理这些局部的交互关系。CoT引入了一种新的局部-全局交互机制,可以更好地处理这种问题。同时,CoT还采用了一种新的层次化的特征融合方式,可以提高模型的性能。

 2020-ViT
2020-ViT

