观看李沐视频 阅读VIT论文
视频链接:https://www.bilibili.com/video/BV15P4y137jb?spm_id_from=333.999.0.0
论文链接:https://arxiv.org/pdf/2010.11929.pdf
- 结论:在足够多的数据上做预训练,也可以不需要卷积神经网络,而使用Transformern
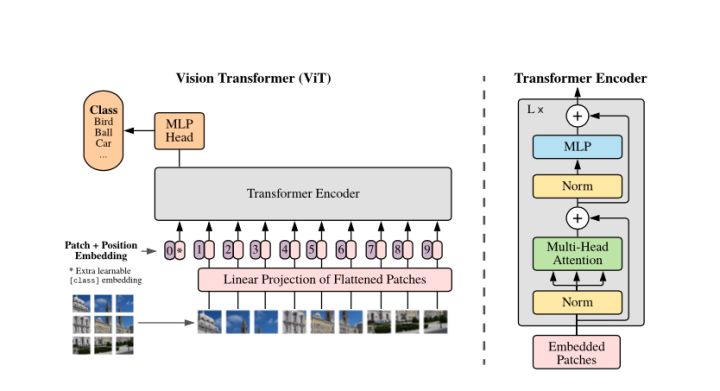
回顾transformer
- transformer的自注意力引入到图像领域复杂度非常高
- 有些工作降低序列长度
- 把网络的特征图当作transformer的输入
- 到卷积网络后面的层的feature map的大小会比较小



